



The Rise of Intelligent Inference. Ship First, Perfect Later.
Why “Imperfect” AI Apps Are Winning

If 2023 was the year of AI prototypes and 2024 was the year of AI production, then 2025 will be the year of practicality.
There’s now a repeatable playbook for how GenAI apps get shipped:
Days-to-weeks: Prompt engineering of a frontier model (GPT-4.1, DeepSeek R1, Sonnet, etc.) into a functional prototype.
Weeks-to-months: Prove the app has product-market fit.
Weeks-to-months: Optimize the hell out of it.
Step 1 gets all the hype. Twitter threads, leaderboard screenshots, and prompt hacks. But the real technical and economic value? It’s happening in the transition from steps 2 to 3—where apps evolve from “it works!” to “it works well and efficiently.”
The secret that most don’t talk about is that teams are intentionally shipping AI apps that aren’t perfect yet.
It’s not perfect, but we needed to start showing value.
This is something I hear again and again from customers. They deploy a rough version, prove some ROI, and only then circle back to fix quality and latency. It’s a radical inversion of the old-school mindset of “perfect, then ship.” In GenAI, it’s ship, then perfect.
This shift is why I believe intelligent inference is the next major wave in AI infrastructure.
🧠 What Is Intelligent Inference?
We originally built Predibase so developers could fine-tune a model, then deploy it. But that’s not what happened in the real world.
Instead, teams skip the upfront fine-tuning and deploy base models first—just using prompt engineering or RAG to get started. Once live, they shift their focus to improving the system over time.
Intelligent inference is about exactly that: inference systems that learn and improve with use. Not just serve tokens—but get better the more they're used.
They do this by combining:
Smart infrastructure (cold-start reduction, autoscaling, GPU orchestration)
Model-level optimizations (Turbo LoRA, speculative decoding)
Feedback loops that improve output quality in production
Let’s break down what this looks like in practice.
🔍 Use Case #1: Making Models Faster with Every Inference
Latency isn’t just a UX problem—it’s a cost problem. The faster your model generates tokens, the more throughput you get per GPU, the lower your total cost of ownership.
Speculative decoding—where the model predicts multiple tokens ahead—is one powerful way to accelerate LLMs. But it works way better when the speculation is tuned to your actual app traffic.

That’s what we built Turbo LoRA for.
It automatically trains speculators on your domain-specific traffic—meaning your model gets 2–3x faster just from serving more requests. No model swap, no code change. Just more throughput, less latency.
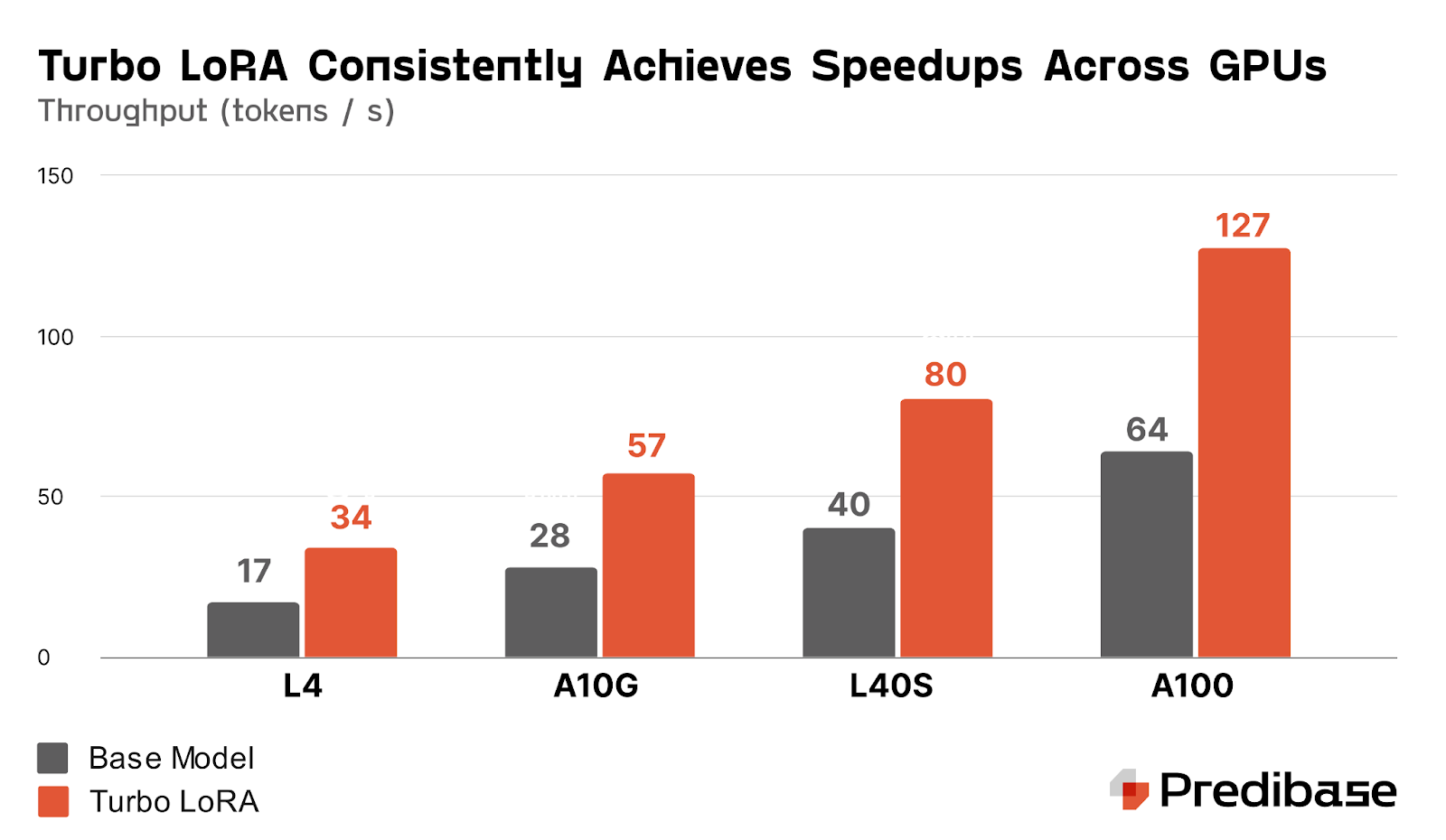
🔍 Use Case #2: Improving Output Quality in the Wild
Most LLM apps fail quietly. The outputs look plausible… but they’re wrong or low-quality.
Intelligent inference closes the loop:
First, log all prompts and responses.
Then let humans correct failures (or flag great responses).
Over time, generate a “golden dataset” for targeted fine-tuning.
We’re also seeing next-gen approaches emerge—like reinforcement learning from human feedback (RLHF) and preference modeling—that require less explicit labeling.
These systems don’t just serve—they learn.
💡 Why Smarter Inference Wins the GenAI Race
Today, LLM inference feels commoditized. Everyone’s hosting the same models, racing to the bottom on price.
Intelligent inference flips that dynamic. It’s not about who hosts DeepSeek-R1. It’s about how well they help you:
Slash latency
Boost quality
Adapt to your use case
Learn from your users
And most importantly—do all that without retraining or blowing your infra budget.
We built Predibase for this exact future. And we’re just getting started.
If this post made you rethink how you fine-tune AI, subscribe.
Got thoughts? I read every comment—drop yours below.